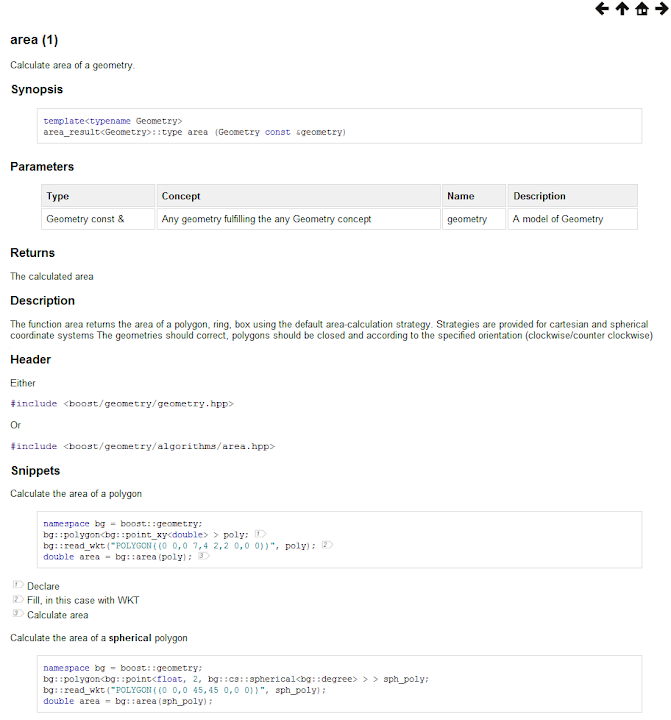
Range, return types and references
During
BoostCon
2009 the
keynote
speaker was
Andrei
Alexandrescu, who wrote the book
Modern
C++ Design in 2001. Andrei held a fabulous
presentation with
the name
"Iterators
Must Go",
in which he point out several serious drawbacks of iterators. Iterators
have been the basic mechanism to use the Standard
Template Library classes, so this speach was revolutionary, and
enjoyable. Andrei not only critized iterators, he also gave an
alternative:
ranges.
Ranges are for him the basic piece.
The keynote was the forenote for an article that Andrei wrote, now with
the title
"On
Iteration". The title is changed into a more subtile, but the
message is more
or less the same. I quote:
"STL
iterators are marred by lack of safety, difficulty of usage, difficulty
of definition" .
Before BoostCon '09 with its famous keynote, I already knew the
Boost.Range
library quite well. Most of the algorithms in
Boost.Geometry are based on ranges. We use Boost.Range everywhere.
Ranges are very nice. A std::vector is a range, but a std::pair of
iterators is also handled as a range, and a Boost.Array is also handled
as a range, and you can create your own ranges. Yes, like iterators,
but ranges are more elegant.
Andrei Alexandrescu mentioned Boost.Range during his keynote, of
course. He said that Boost.Range was a good start, but should be worked
out way further. Until now, that has not been realized as far as I
know. But even without changes, Boost.Ranges are far more convenient
than iterators.
Iterators
People reading this blog will know iterators and otherwise will have
stopped reading here. However, I like to explain the very basics
shortly because of the point
that Andrei made: "iterators are unnecessary difficult", I've
always found that. This is how standard iterators work:
std::vector<int>
a;
// fill a
for
(std::vector<int>::const_iterator it = a.begin(); it !=
a.end(); ++it)
// do something with
*it
When I first worked with the std::library, somewhere in 199X, I refused
to do this and wrote:
for (int i = 0; i
< a.size(); i++)
// do something with
a[i]
This is half the size, easier to write, easier to read. But it is
(much) less efficient and should therefore not be done like that.
Note also
that C++ programmers always write ++it and not it++ because it is
slightly (and detectably) more efficient.
Boost.Ranges
A Boost.Range is a sort of view on a std::vector, or on any other
iterable instance. Boost.Range still defines and works with iterators.
It is another level of abstraction above the std:: library. With
iterators you iterate like this (still vector a):
for
(boost::range_iterator<std::vector<int>
const>::type it = boost::begin(a); it != boost::end(a); ++it)
// do something with
*it
Hey, this is even much longer! Yes, in this sample this is
true
and in general it is true, but ranges are normally (at least within
Boost.Geometry) used in a template environment, where it becomes:
for
(typename boost::range_iterator<Range const>::type it =
boost::begin(a); it != boost::end(a); ++it)
Not shorter but more generic: a Range can be anything.
There
are shortcuts as well: with BOOST_FOREACH or BOOST_AUTO. They are
macro's, so often avoided, but they make things more readable and can
save template metaprogramming, see below. But first we will see why
ranges are so convenient.
From Iterators to Ranges
Boost.Geometry supports geometry algorithms such as
distance. They are
defined in a generic way, so
template
<typename Geometry1, typename Geometry2>
double distance(Geometry1 const& g1, Geometry2 const& g2)
(The real version does not have the
double there but a
metafunction). With distance users can calculate the distance between
two points, or a point and a line (linestring), or a point and a
polygon, etc.
The earlier version of Boost.Geometry (then called GGL), before going
to ranges,
could calculate the distance to of a part of a linestring by specifying
two
iterators as well:
template
<typename Geometry1, typename Iterator>
double distance(Geometry1 const& g1, Iterator it1,
Iterator it2)
This is great functionality, but it is completely inconvenient to
implement:
- all other functions are generic, having two arguments, why
does this one has three arguments?
- all other functions are reversable, the distance from a
point to a line, and from a line to a point, both result into the same
implementation. For iterator support we would need to create an
overload having the iterators first
- there are more versions (for example: with a strategy), we
would need those overloads for those two, leading into another
combinatorial explosion (there are more algorithms too...)
When we discussed the GGL previews on the list, Mathias Gaunard
suggested
to use ranges instead of Boost.Geometries and we took this over and
were very glad with this change.
This is quite an argument for ranges instead of iterators in a
template-library environment, and this is why I emphasis this at this
point.
So let me state:
Ranges are compatible with other objects, while iterator-pairs are not.
References
After this lengthy introduction we consider how
iterators and ranges are passed.
Iterators are normally passed by
value.
The main reason for this is explained nicely in
StackOverflow:
by passing by value you can create local copies, like v.begin().
Ranges are normally passed by
reference.
Ranges might be non-copyable containers, so
passing
by reference
is required. Besides the non-copyable issue, a std::vector
is
a
range. You definitely don't want to pass a std::vector by value.
Boost.Geometry's polygon
Boost.Geometry contains models of geometries like
linestring and
ring.
They are defined as std::vector or a std::deque, but handled in the
code as a range. Any linestring or ring fulfilling the Range Concept
can be handled by Boost.Geometry, at least that is the basic idea. A
polygon is more more complex because it might contain holes, in the
definition of OGC and Boost.Geometry. So a polygon has an exterior ring
and zero or more interior rings, defining the holes. The exterior ring
fulfills the Ring Concept, the interior ring is a
Range of Rings, so a
Range of Ranges,
a collection or rings.
Boost.Geometry contains a free function
exterior_ring which
returns the exterior ring by reference. And it also contains a free
function
interior_rings
where the collection of interior rings are returned by reference. Both
functions have a const and a non-const version. Of course they don't
return the rings by value: polygons can be huge geometries, I've
recently processed a polygon of 6 megabytes (in WKT-format). They
should never be returned by value.
Other polygons
With
Boost.Geometry, geometry classes of other libraries can be adapted,
such that Boost.Geometry can run algorithms on them as if it was one of
its own geometry classes. There are examples showing this with libgd's
points, WxWidgets's points, Qt's polygons, etc. With traits classes
these geometry classes can be adapted.
However, until today, polygons were
required
to return the exterior ring and interior rings by reference. But what
if those geometries do not use ranges?
We encountered this adapting
Boost.Polygon,
our sister library within the Boost family.
Boost.Polygon
defines a polygon-with-holes-concept, where iterators begin_holes and
end_holes are returned.
So
after successfully adapting Boost.Polygon's point, rectangle and
polygon (without holes, so we call it a ring) to our library, I started
with the polygon. It is no problem that Boost.Polygon do not use the
range concept internally. Because we can build a sort of proxy,
simulating a range. So the adaptation of a Boost.Polygon
polygon-with-data consists of defining:
- an iterator to iterate through holes
- a ring-proxy with an iterator-pair (point-begin, point-end)
- an interior-ring-collection-proxy with an iterator-pair
(holes-begin, holes-end).
But there was one problem:
Returning local
references?
Local
variables can (of course) not be returned as references. So you can
create ring-proxies, but they cannot be returned... That is to say,
they cannot be returned
as a
reference. Of course, they can be returned by value.
There are several solutions to this problem:
- Change
the Boost.Geometry polygon concept to work with iterators, so
let
it return iterators. This would be quite a lot of rework,
and sounds like going ten years back. So discarded.
- Change
Boost.Polygon's polygon concept. But that is of course not wished and
not possible. Boost.Polygon is now an incorporated library.
Besides that, Boost.Polygon is an
example here, many polygon libraries will have polygon types having no
ranges internally. For
example, shapelib's geometry is just a set of pointers...
Boost.Geometry should handle any geometry. So discarded
- Let
Boost.Geometry's polygon concept return ranges always as values. This
is possible, but the return value for its own polygon should then not be the ring but
a proxy
containing the reference of the ring.
- Let Boost.Geometry's polygon concept return ranges
sometimes as value, sometimes as references
I've
chatted with my companion Bruno Lalande about this. He had the
opinion that we definitely not should go back to iterators. He
suggested the
fourth solution. Let me quote Bruno:
in Boost.Geometry, generic
functions like exterior_ring() or interior_ring() that only forward the
job to the actual adapted function, shouldn't make any assumption on
their return type. Currently they seem to be generic in this regard
since they get the return type by calling a metafunction, but they're
not fully generic because they arbitrarily add a "&" to it.
Boost.Range returns ranges
by
reference and
by
value.
Andrei
Alexandrescu returns ranges in his article, on various places. We might
change our own polygon type, returning proxies to ranges, and returning
them by value. This would be solution 3. However, as long as this is
not necessary, we prefer solution 4, to avoid an unecessary proxy in
between, and to enable range-based polygon-types to return references
to ranges.
Exterior rings should sometimes be returned as values, and sometimes as
references.
So I changed the Boost.Geometry library into
range-return-type agnostic
behaviour.
So let me summarize:
Ranges
can be returned as values or as references
More
metaprogramming
To
implement solution 4 mentioned above, Boost.Geometry's polygon needed
two characters extra: two ampersands. So its traits function ring_type
now reads:
template
<
typename Point,
bool ClockWise, bool Closed,
template<typename, typename> class PointList,
template<typename, typename> class RingList,
template<typename> class PointAlloc,
template<typename> class RingAlloc
>
struct ring_type
<
model::polygon
<
Point, ClockWise, Closed,
PointList, RingList, PointAlloc, RingAlloc
>
>
{
typedef typename model::polygon
<
Point, ClockWise, Closed,
PointList, RingList,
PointAlloc, RingAlloc
>::ring_type&
type;
};
where the ampersand is added... Meaning, the ring-returning-type is now
a reference!
Of course some more changes were necessary, but not more. The free
function
exterior_ring
now uses a meta-function to define its return type. That meta-function
uses the traits-function ring_type, so returns sometimes a reference,
sometimes a value. For const and non-const, another metafunction is
created:
template
<typename T>
struct
ensure_const_reference
{
typedef typename mpl::if_
<
typename boost::is_reference<T>::type,
typename boost::add_reference
<
typename boost::add_const
<
typename boost::remove_reference<T>::type
>::type
>::type,
T
>::type type;
};
I
like metaprogramming. If the type was a reference, it removes it, adds
a const, and adds a reference again. If it was not a reference, it
keeps it unchanged. This is type calculation, metaprogramming.
Iterating
through const/non const collections of values/references
At
every place where Boost.Range iterators were used to iterate through
interior rings, a change was necessary. This was possible creating
another metafunction, but Bruno suggested to use BOOST_AUTO here. This
avoids new metafunctions, and makes all iterations more readable. This
works perfectly for both const and non const iterators, so in fact it
is all much more simple than before. Loops are now written like this:
for (BOOST_AUTO(it,
boost::begin(interior_rings(polygon)));
it !=
boost::end(interior_rings(polygon));
++it)
This
BOOST_AUTO word, which anticipates the C++0x auto keyword, saves
defining and declaring metafunctions all the time. It is a macro (yack)
but very valuable here, also because if we change things another time,
this can stay as it is now.
One thing is noteworthy, there are two calls to interior_rings
returning (in the return-by-value case) two copies. Because these
copies are suspected to be proxies, containing references to the
original (single) object, the iterator-behaviour will be all right,
they are both pointing to the same original range.
However, better
safe then sorry, better defensive, so we should write here:
BOOST_AUTO(irings, interior_rings(polygon));
for
(BOOST_AUTO(it, boost::begin(irings)); it !=
boost::end(irings);
++it)
which might be also more efficient in some cases.
Conclusions
- Ranges are great.
- Ranges are compatible with other objects, while
iterator-pairs are not
- Ranges can be returned as values or as references
- Boost.Geometry's polygon concept uses ranges, allowing
adaption of other polygon types using implementation of range proxies